阿里云SIGCOMM22论文阅读

阿里云在今年的网络顶会SIGCOMM上发表了一篇论文:”From Luna to Solar: The Evolutions of the Compute-to-Storage Networks in Alibaba Cloud”。
该文章介绍了阿里云在EBS存储的应用背景下,计算节点和存储节点间网络通信的演进过程。由于文中介绍的网络架构已经在阿里云内部大范围应用,对于同样提供EBS服务的云厂商来说,有很好的指引性。
背景介绍:EBS网络
弹性块存储(EBS)是云厂商提供的标准服务,以云主机或者裸金属可见的虚拟磁盘的形式被用户使用。有按需分配磁盘数量、按需分配磁盘容量的特点。
阿里云EBS的总体架构如下图所示: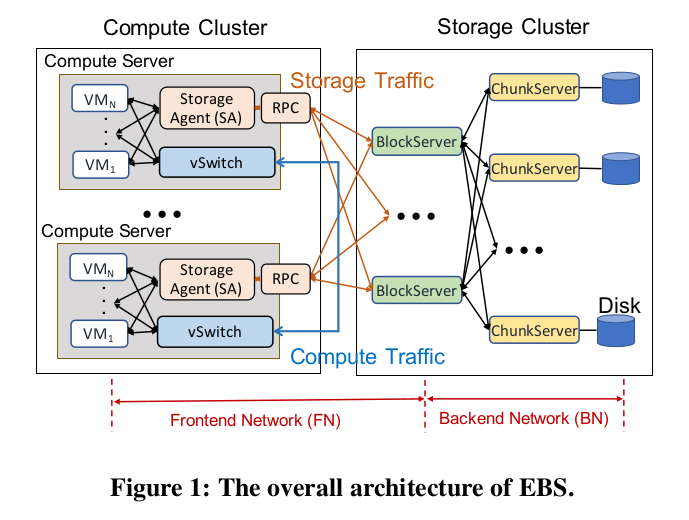
虚拟机磁盘的I/O数据传输到计算节点服务器上的存储客户端(SA),SA通过RPC与存储集群的Block Server交互,最终数据经由Block Server写入Chunk Server的磁盘。因此可对EBS网络做如下切分:
- 前端网络(FN):连接计算节点和Block Server的网络,也是这篇论文关注的部分。
- 后端网络(BN):连接存储节点间的网络。
具体到SA的处理流程,一次写请求的处理流程如下:
- SA接收到虚拟磁盘的写请求。
- 查询QoS Table,获取虚拟磁盘的服务等级和当前用量信息,酌情进行限速。
- 生成CRC校验。
- 进行数据加密(可选); 同时查询Segment Table,获取的目标Data Segment及对应的Block Server。
- 将元数据和数据写入Buffer。
- 发送一个或多个RPC将数据和元数据发送给Block Server。
- Block Server 收到写请求。
- Block Server将请求发送给对应的后端Chunk Server。
- 完成三副本写入后,Block Server发送回应。
下图是图形化的展示 :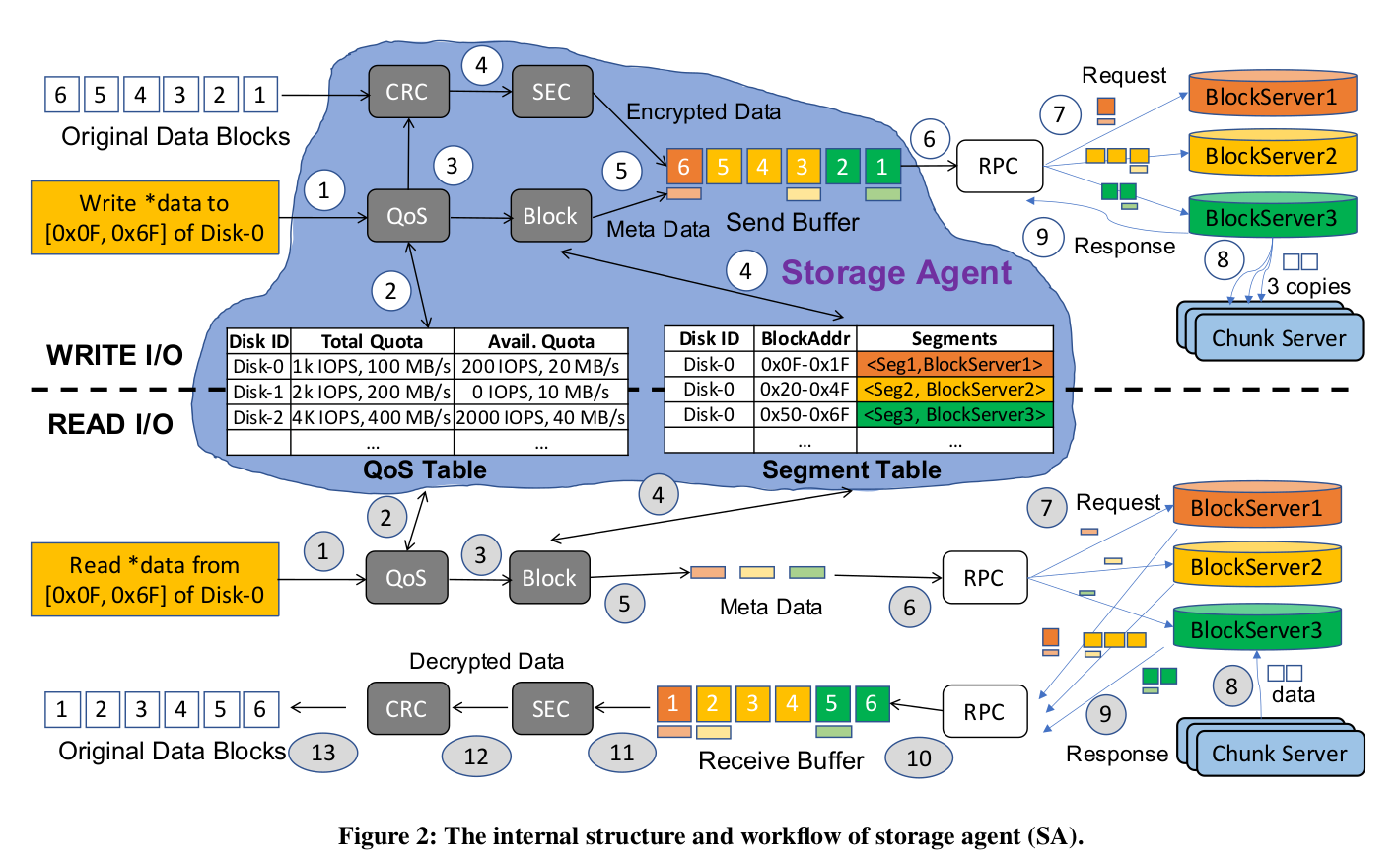
可以看到在整个I/O处理中,SA扮演了很重要的角色。I/O过程中,SA的查表、校验、加解密及数据传输,都将消耗计算节点的资源。
EBS前端网络的特点
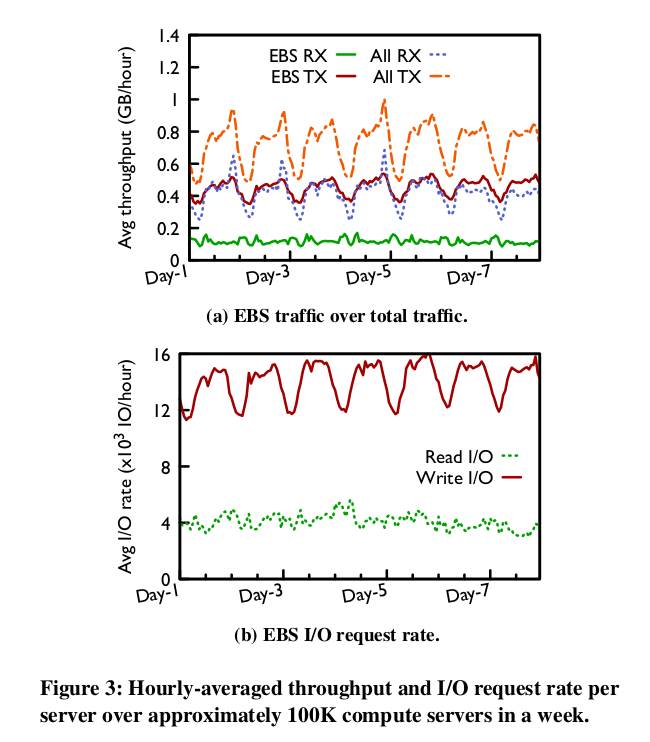
阿里云分析了其线上10W台服务器,有如下总结:
- EBS以写I/O为主,其流量占服务器流量的大部分:EBS流量占到发送流量的63%,占总流量的51%。结合下图能看出来EBS流量超过70%都是发送流量(写I/O)。同时文章也提到了,单台线上物理服务器的平均IOPS在20W左右。
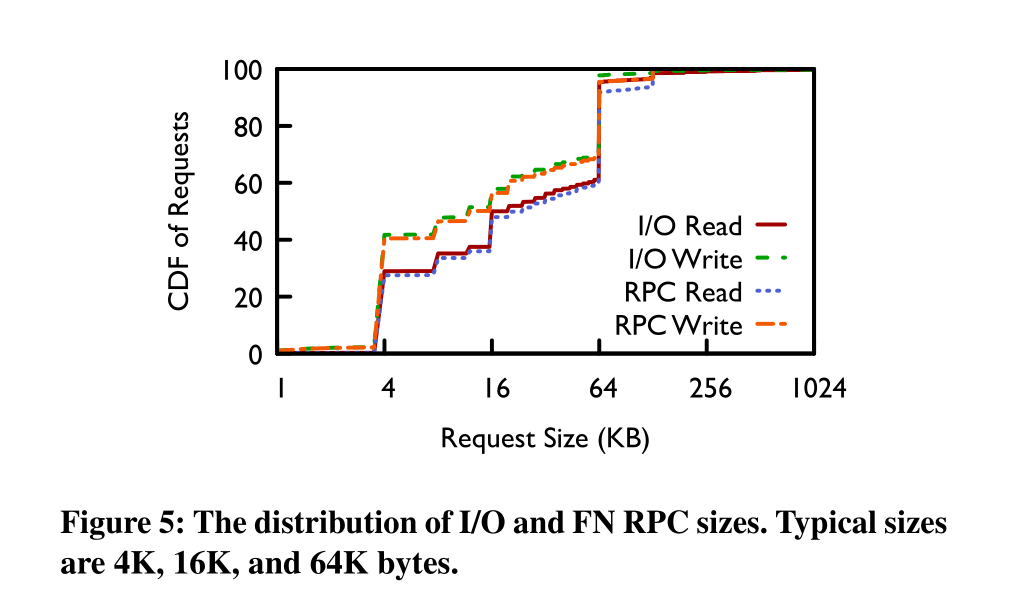
I/O不大: I/O请求均小于128K,40%的I/O小于4K。由于小I/O对延时更加敏感,因此阿里判断其EBS流量主要为延时敏感型。下图是I/O大小分布情况:
I/O延时LUNA和SOLAR优化明显: I/O延时对比如下图所示,可以看到使用内核TCP的FN和BN均有较高的延时,远大于SSD设备本身的写入和读取延时。而LUNA使用用户态TCP实现后,对读写I/O场景FN和BN的延时都有大幅度的降低。而LUNA应用后,可以发现SA在读写延时中成为瓶颈,SOLAR则一定程度上解决了这个问题。SOLAR在4KB写I延时上优化效果十分明显。
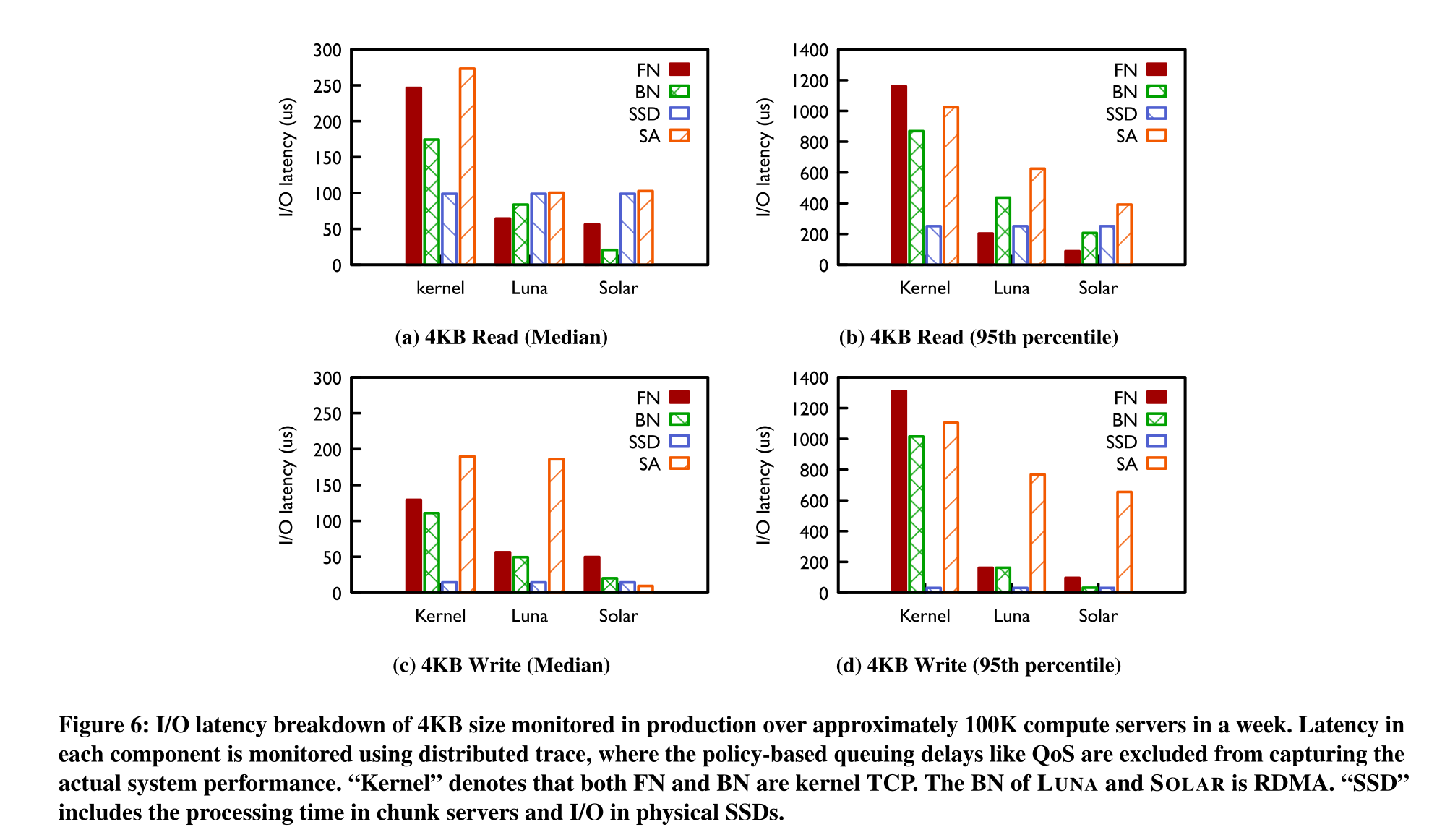
这里补充下SSD硬件设备的延时作为参照,如Intel P4510 4TB SSD磁盘,其4KB随即读取延时为95us,随机写入延时为25us。
LUNA
由于内核协议栈在延时层面有较大开销(几百微妙到毫秒级),因此,实现低延时有两种主流方案,一种是基于软件bypass 内核的方案,如Intel DPDK等; 另一种使用基于硬件的bypass内核方案,比如RDMA。LUNA 是阿里为了低延时,为FN实现的软件用户态网络方案,和腾讯云的zTcp类似。
阿里在BN端使用了RDMA,在FN侧为什么要使用软件方案,其基于如下考虑:
- 扩展性:由于FN负责连接计算节点到存储集群,考虑到计算节点的数量,FN需要将扩展性作为重要的设计因素。另外在保持大量连接的同时,FN还需要保障其高性能和高可靠性。相比之下,BN需要连接的节点数量要少得多。
- 互操作性:由于不同存储集群的部署时间不同,其所用网卡硬件可能存在差异。FN需要保持对不同硬件配置的兼容性。而单个存储集群内,则硬件配置可以保持一致。
文中也提到,在LUNA开始开发的2017年,RoCEv2并不成熟,有连接数目到达一定规模总体网络带宽急促下降,及不同厂商、不同型号网卡间不兼容的问题。因此基于前述两点及RDMA应用的问题,阿里选择使用软件方案,也就是LUNA。
从2019年发布之后,LUNA几乎已经部署到所有的阿里云EBS集群,2021年Q1全量部署之后,相对于2019年Q1,EBS的整体延时下降了64%,IOPS增大180%。延时及IOPS的进化如下图所示: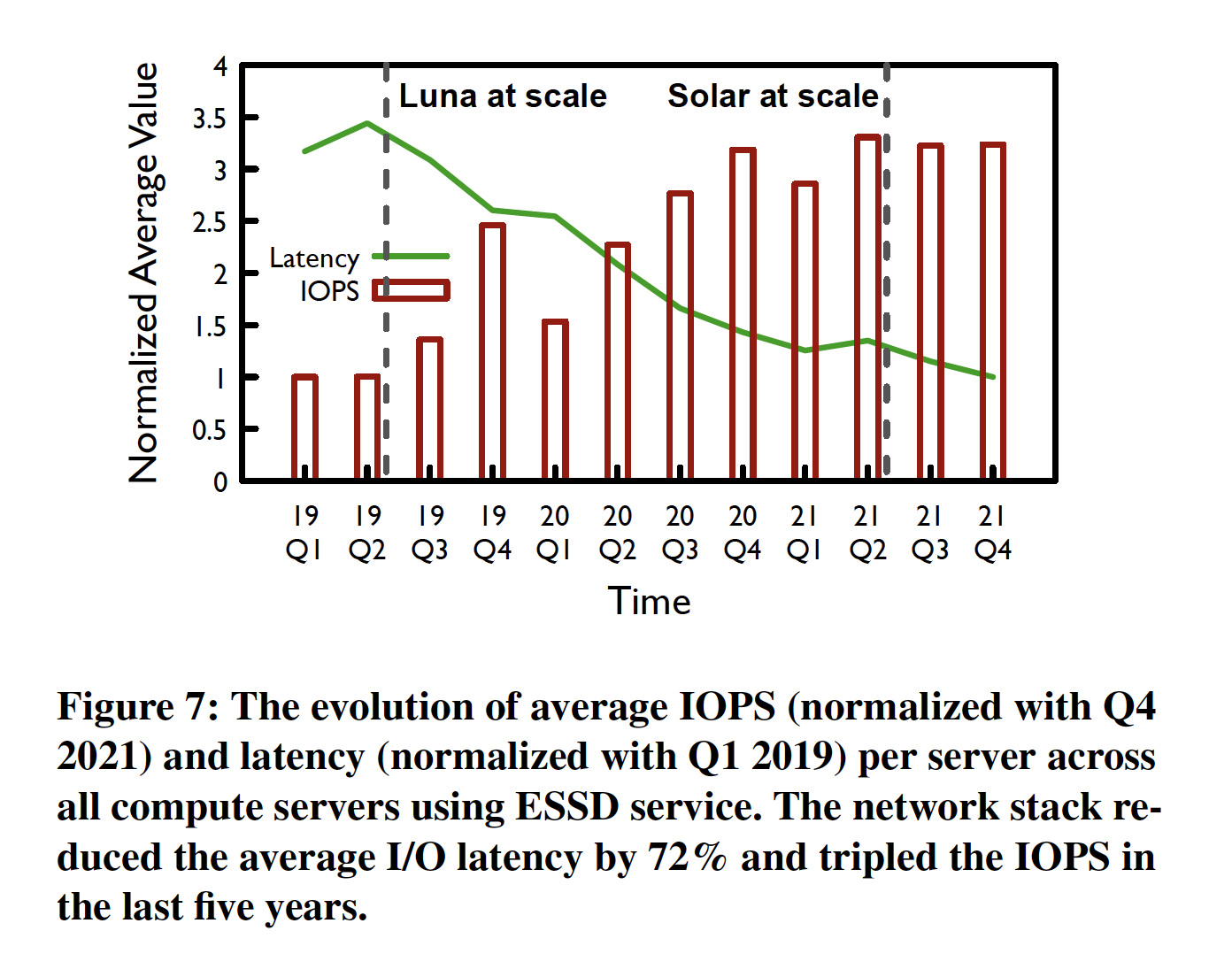
下表则展示了,LUNA和内核TCP在性能和开销上的对比。在2x25G下,LUNA相对于内核协议栈,延时降低了80%,仅需要1个CPU 核即可打满50G带宽。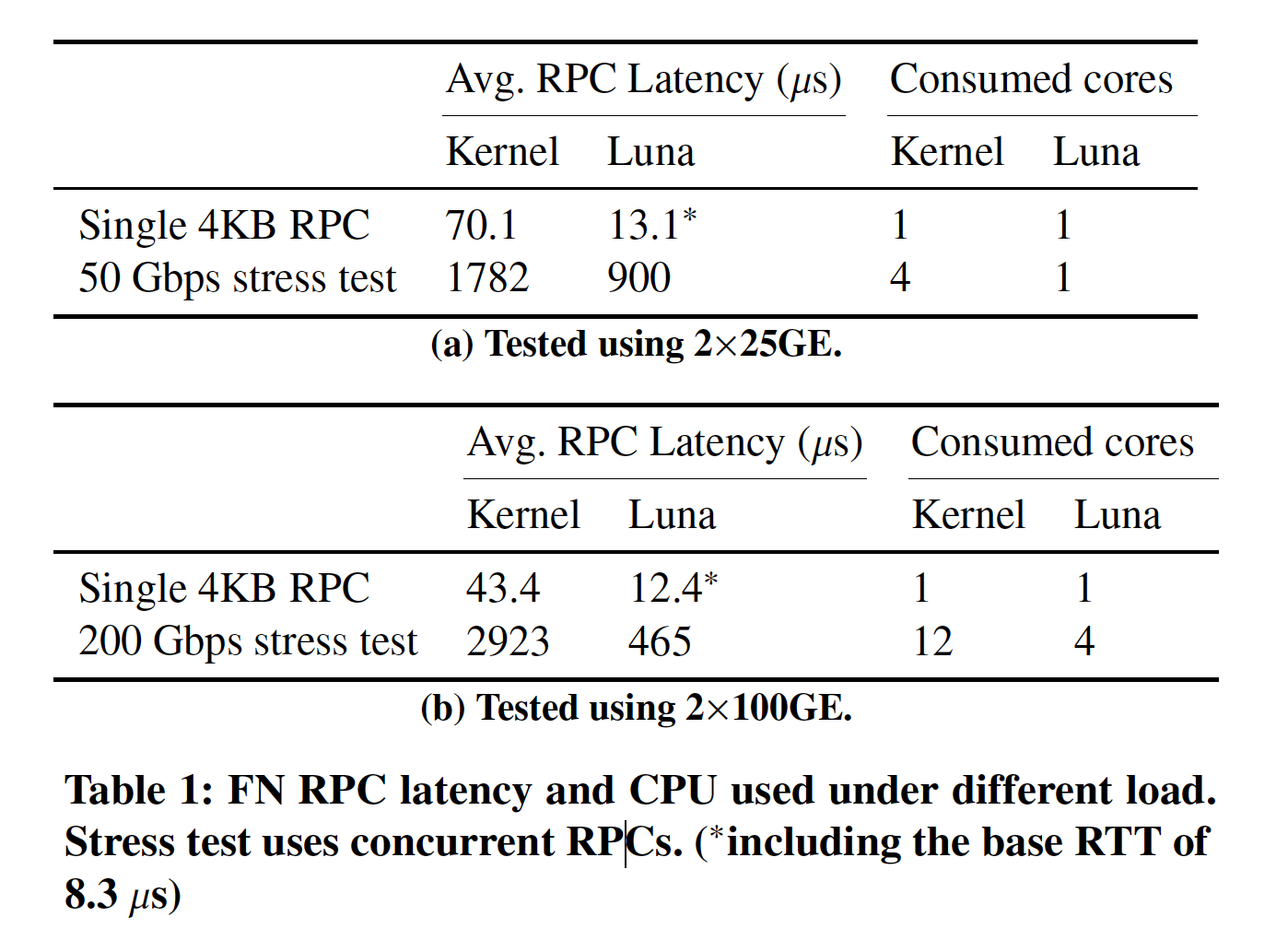
LUNA有前面所说的突出优势,在大面积应用LUNA之后,一些问题凸显出来:
- SA成为性能瓶颈: 在应用LUNA之后,端到端延时的瓶颈变为SA。SA有复杂的计算逻辑,比如CRC、加密、查表等。能不能将这部分交由硬件处理?
- 随着网路能力的进一步提升,软件方案难以持续:尽管LUNA不在是瓶颈,但是在实际应用中,其占用了很多的CPU资源。对于2x100G网络,其需要4个CPU核心,对于后续的2x200G,2x400G来说,将必须吧这部分网络处理放到硬件上。
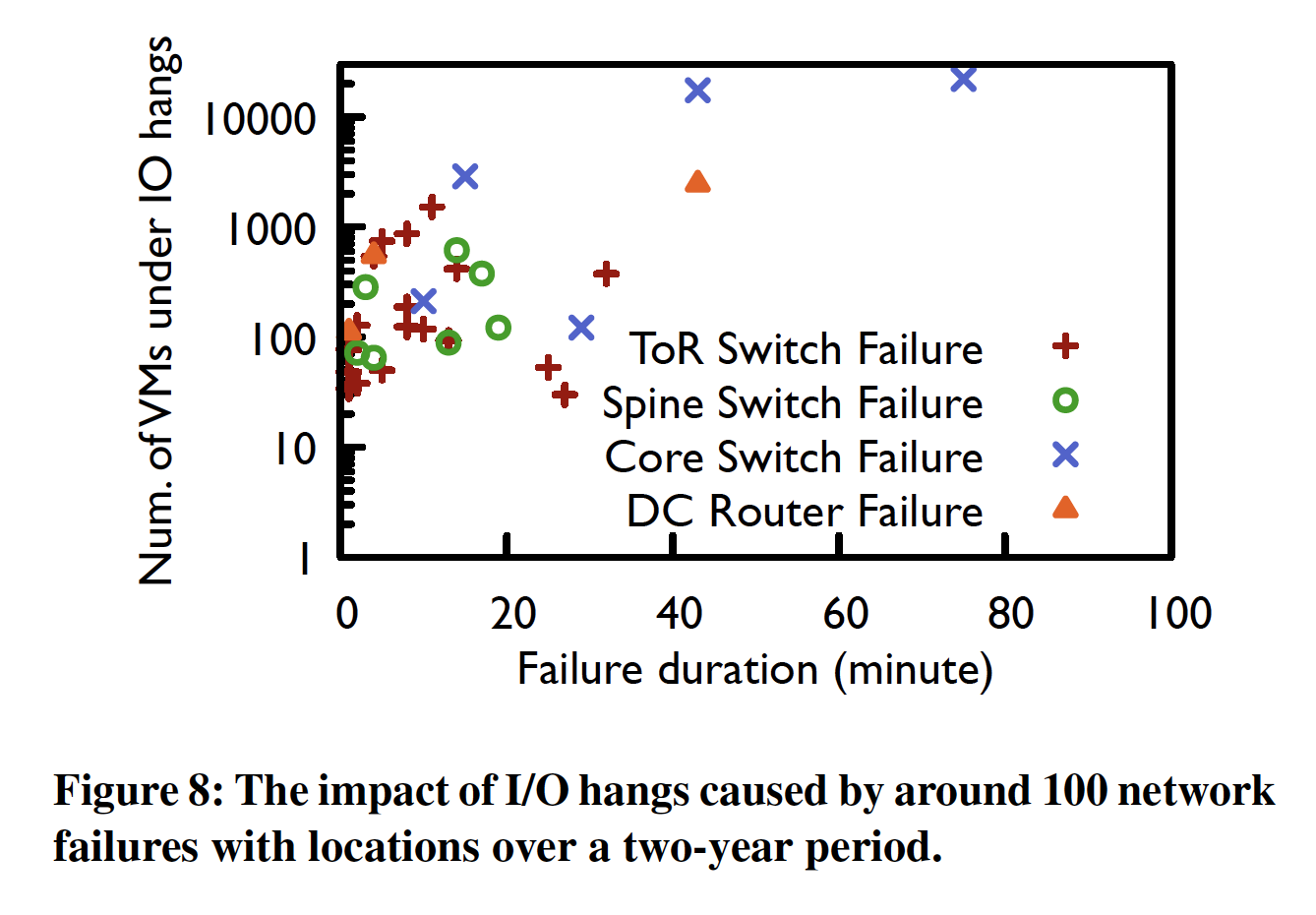
- 网络故障对存储的影响是灾难性的: 当发生网络故障,LUNA只能等待网络恢复,而网络恢复时间需要较长的时间,可以达到分钟级,在这个过程中,EBS I/O将夯住。下图展示了在网络故障下,大量的虚拟机I/O无法完成。
- 应用DPU后遇到的内部PCIe带宽问题:在使用DPU(神龙)后,LUNA运行于DPU卡上的CPU,,数据需要在卡上的FPGA和卡上的CPU间通过内部PCIe连传输。这个内部PCIe连接, 也成为了网络带宽和延时的瓶颈。
SOLAR
2018年开始,阿里开始研发SOLAR系统。SOLAR有两个设计目标:一个是降低DPU上的CPU开销并解决CPU和FPGA间的PCIe带宽瓶颈问题;另一个是通过主动的路径切换来发现并规避网络故障。
SOLAR和LUNA及RDMA架构的对比,如下图所示: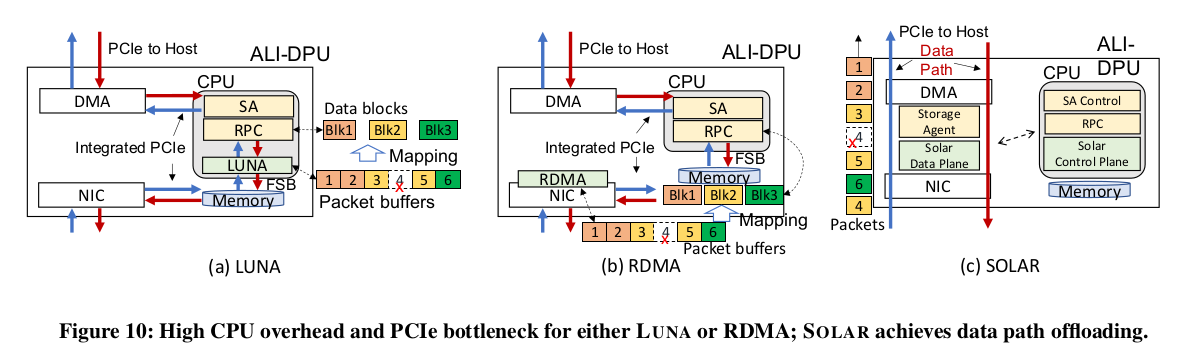
SOLAR的实现有三个挑战:
- 网络栈和SA都是复杂的、有状态的软件系统,要想在FPGA的有限资源上实现是比较难的。
- 实现的可扩展性。
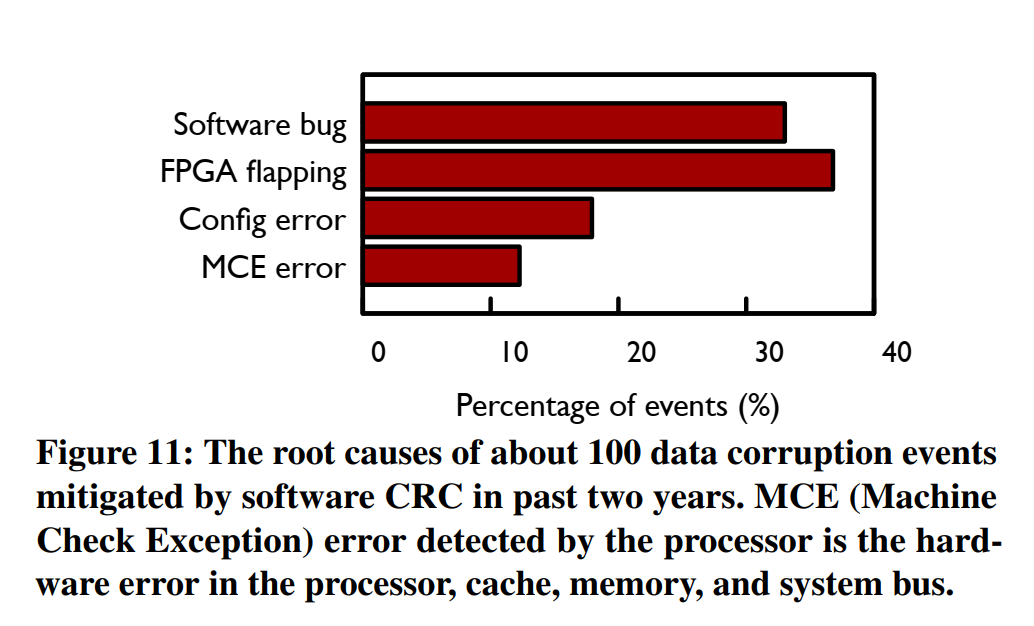
- FPGA 硬件是易出错的。阿里的实际观测,37%的线上数据损坏,由FPGA硬件导致。分布如下图所示:
SOLAR的实现思路是将存储实现和网络栈融合起来,消除FN中的数据包缓存、以及数据包到存储系统数据块的转换。具体来说,就是“一个数据块一个数据包”。这样的设计有如下的好处:
- 不再需要数据包缓存,用于将数据包拼成数据块。
- 不再需要CPU处理。DPU内网络处理和存储处理直接衔接。
- 更少的状态维护。不需要维护数据包到存储数据块的映射。
- 对多路径的兼容。由于所有的数据包都相互独立,其对数据包重排不敏感,这也简化了多路径的实现。
- 易于实现。“一个数据块一个数据包”的设计和当前的系统实现吻合,实现对当前系统修改不大。
下面来看看SOLAR 具体的读写流程。
SOLAR的读写流程
写流程
如下图所示: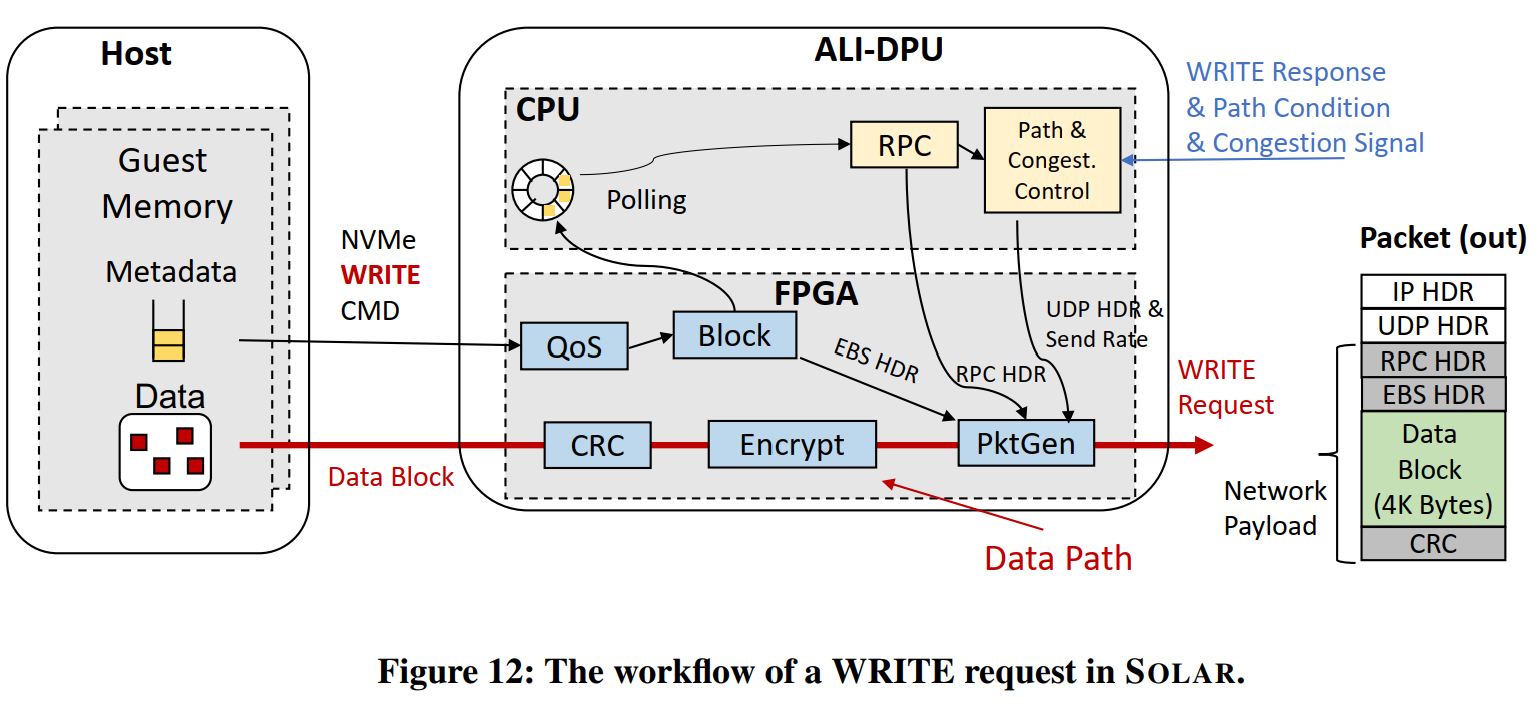
- Guest 通过NVMe命令向DPU发起写请求。
- QoS 模块对写请求进行带宽控制,Block模块将VD的逻辑地址翻译为远端Block Server 物理磁盘的具体Segment地址。(这里涉及到对QoS和Block映射两个表的查询)
- DPU上的CPU 通过Polling发现了该写请求,并对每个I/O准备RPC和UDP Header。
- FPGA同时通过DMA获取该次请求的数据,通过CRC模块计算CRC,如果需要通过SEC模块进行加密。
- 最终,由PktGen模块发送数据包。
读流程
为记录数据块,读流程涉及到如下图所示: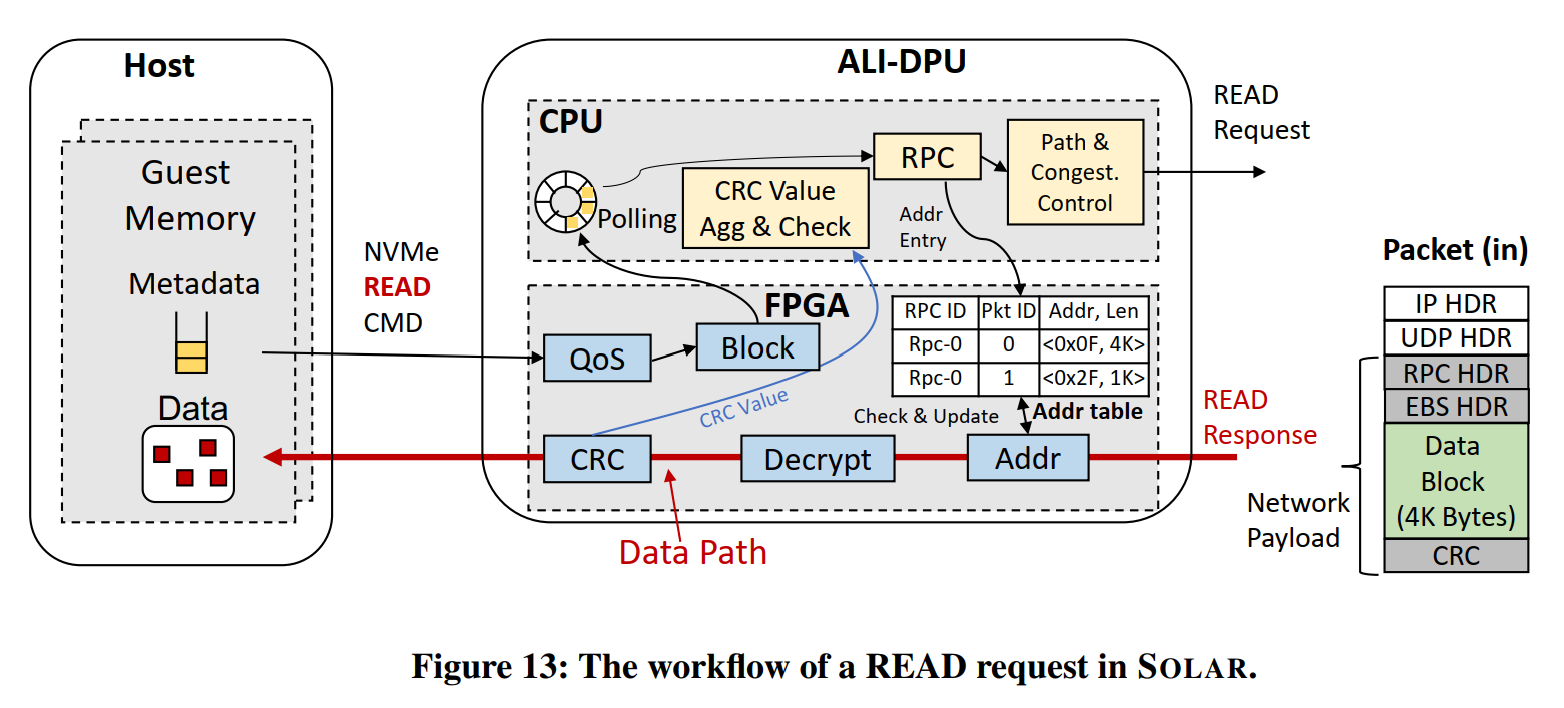
- Guest 通过NVMe命令向DPU发起读请求。
- 与写请求类似,QoS模块和Block模块进行处理。
- RPC模块在ADDR表中增加一项,ADDR表记录了RPC ID、I/O请求ID 和对应的Guest内存地址。
- DPU上的CPU发送RPC请求。
- DPU上的FPGA收到请求的返回信息,并根据ADDR表的记录进行处理,处理后,清除该表项。
- DPU上的FPGA完成CRC和DMA处理,并将头部和包元数据信息发送至DPU上的CPU进行数据完整性校验。
- 最终,DPU上的CPU通知Guest I/O处理完成。
通过上面的两个流程,可以看到SOLAR将数据面卸载到了FPGA上,但是每次I/O仍需要DPU上CPU的介入处理。
SOLAR的应用
2020年起,SOLAR在阿里部署了超过10W台服务器,有如下的优势:
- SOLAR 提升了I/O性能:由于部署了SOLAR,EBS整体延时降低25%,对于4KB写请求,延时降低69%。同时SOLAR相对于LUNA也提高了资源利用效率,单核心的带宽和IOPS分别提高了78%和46%。并且论文也提到,虽然SOLAR降低了SA的平均延时,但是依然有较高的长尾延迟存在。该延时是因为目前SOLAR依赖DPU上CPU来进行拥塞控制,在I/O压力较大的情况下,CPU的负载比较高。
- SOLAR避免了因为网络故障导致的I/O夯死:在线上环境,Guest 虚拟机每年因为网路故障,几十起I/O夯死,在SOLAR部署的两年间,这个数字降为0。
- 硬件资源消耗较少,如下图所示:
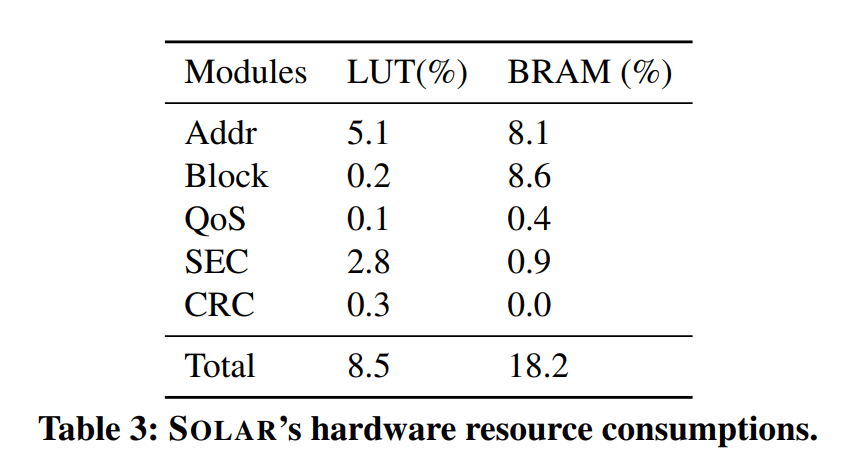
SOLAR的一些经验
- 网络速度正变得越来越快,越发接近PCIe速度。再这样的背景下,SOLAR这种bypass PCIe通道的实现就能避免其性能瓶颈,阿里认为bypass PCIe是高性能网路协议的长期需求。在这种实现下,SOLAR单CPU 核心可达成150K IOPS的性能。
- 使用jumbo frame的优缺点: 使用大包传输,有因网络拥塞增大延时的风险。这里阿里做了一些优化,比如交换机为SOLAR使用单独的队列,并使用更细粒度的拥塞控制算法,选取适中的包大小(4K而不是8K)等。
- 将EBS与DPU结合:存算分离的架构在一些资源受限的场景(比如:边缘计算或者私有云)会带来较高的网络通信开销,这时候可以考虑将Block Server整合到DPU中。