课程仓库: https://github.com/garry-x/llm-course
本地阅读: clone 后 ./serve.sh serve
启动,默认 http://localhost:8080
状态: 持续更新中,本文基于 2026-06-15 的 commit
e3e2b08(345 commits)
一句话定位
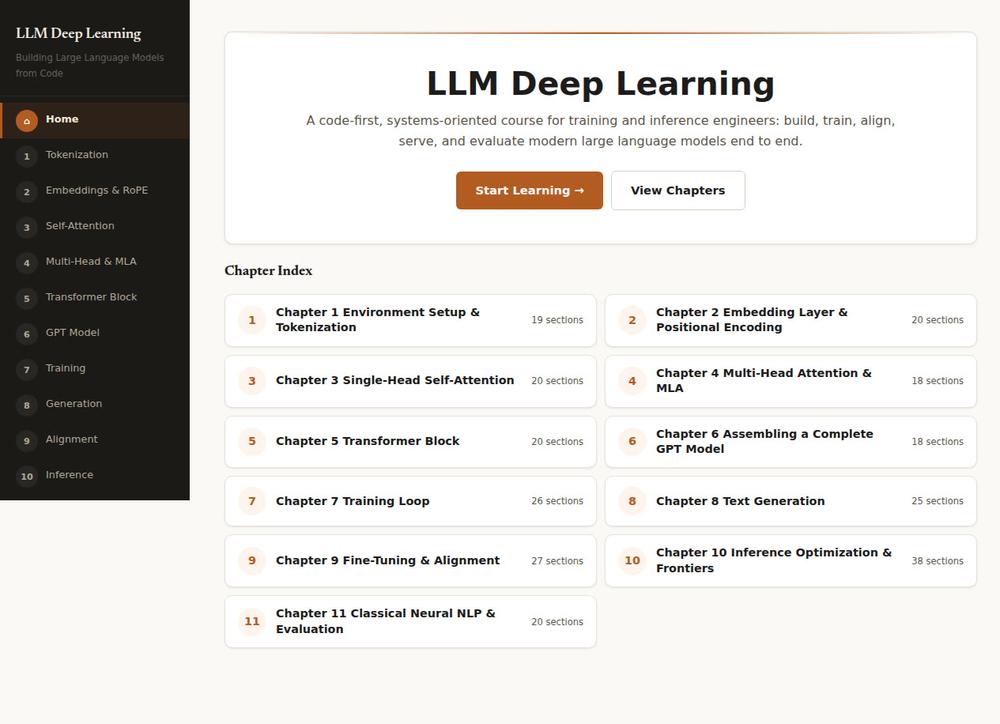
这是一门 code-first 的 LLM 实战课:不用调 API、不追新版本,而是用 Python + PyTorch 一行行写出 Tokenizer、Attention、Transformer Block、GPT、Training Loop、Inference Optimization,最终拼成一套能训、能生成、能对齐、能部署的完整工程系统。
这课为什么值得看
市面上讲 LLM 的资料不少,但大多分两类:一类是"读论文看公式"的理论课,一类是"调包跑 demo"的项目课。这门课卡在中间,做了件少见的事——把公式翻译成 PyTorch 张量,把论文里的架构改写成工业级代码。
具体一点:
- 11 章 / 251 个 section,从 BPE 到 vLLM 级推理优化全覆盖
- 每章都有编程作业:
starter.py+reference_solution.py+tests.py,写完能跑测试验证 - 工业级架构案例:MLA、MoE、FP8、GRPO/DAPO/GSPO、稀疏/压缩 Attention、Linear Attention、SSM/Mamba、Learnable Residual——不是列名词,而是用代码理解它们解决什么瓶颈
- 9 份工程附录:符号约定、PyTorch 速查、ML 基础桥接、经典 NLP 衔接、扩展阅读清单
课程的副标题很直白:
Starting from code, 11 chapters to build a complete large language model engineering system.
11 章地图
| 章节 | 核心问题 | sections |
|---|---|---|
| Ch01 Environment Setup & Tokenization | 文本怎么变成 token ID(BPE) | 19 |
| Ch02 Embedding Layer & Positional Encoding | token 怎么变成向量,位置怎么编码 | 20 |
| Ch03 Single-Head Self-Attention | 单头注意力的张量流 | 20 |
| Ch04 Multi-Head Attention & MLA | 多头、KV 复用、MLA | 18 |
| Ch05 Transformer Block | 残差、Norm、FFN、Block 组合 | 20 |
| Ch06 Assembling a Complete GPT Model | 把上面拼成一个能 forward 的 GPT | 18 |
| Ch07 Training Loop | next-token prediction = MLE,loss / PPL / 优化器 / checkpoint | 26 |
| Ch08 Text Generation | 采样策略、KV Cache、解码 | 25 |
| Ch09 Fine-Tuning & Alignment | SFT / LoRA / DPO / GRPO / RFT,行为改写 | 27 |
| Ch10 Inference Optimization & Frontiers | KV Cache、稀疏/线性 Attention、量化、RAG、Agent | 38 |
| Ch11 Classical Neural NLP & Evaluation | RNN / LSTM / seq2seq / BERT,与现代 LLM 的联系 | 20 |
Ch10 是目前最厚的一章(38 个 section,约 235 分钟阅读),信息密度很高:
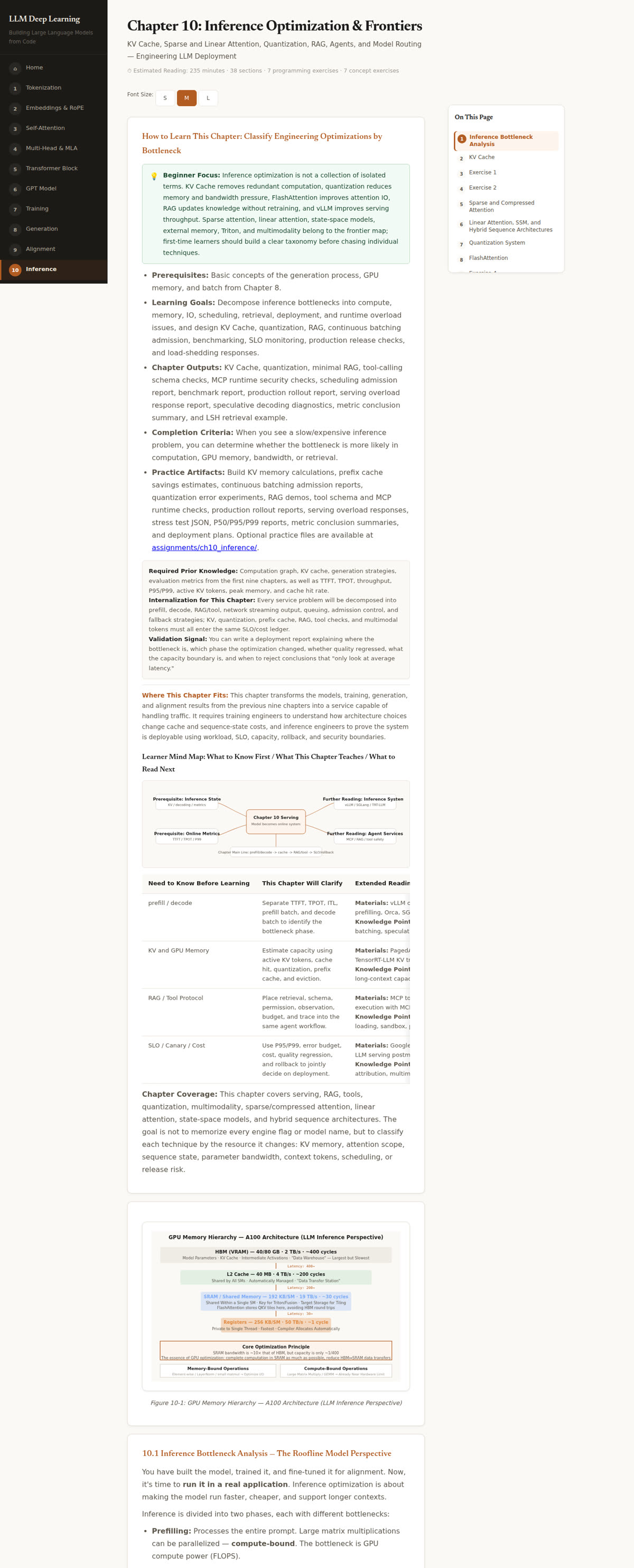
这一章的核心不是"罗列 KV Cache / FlashAttention / 量化 / RAG"这些名词,而是教你按瓶颈(计算、内存、IO、调度、检索、部署)给优化技术分类,看完能判断一个慢/贵的推理问题卡在哪个环节。
四个值得关注的细节
1. 每章都有"完成标准"
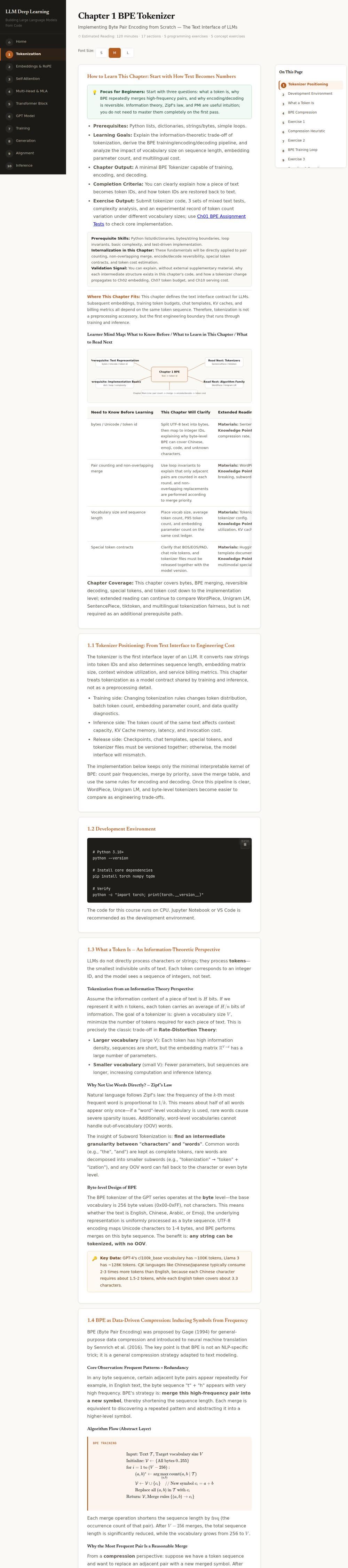
不是看完视频就算学完。每章开头给出 Prerequisites → In-Chapter Internalization → Validation Signal 三段,结尾给出 Completion Criteria。比如 Ch01 BPE 的标准是:"你能解释一段文本如何变成 token ID,token ID 如何还原成文本"——能用自己的话复述,才算过。
2. 数学和代码不拆成两门课
需要矩阵乘法、链式法则、softmax
求导时,就在当下章节展开,不另开"数学先导课"。附录
docs/math-prerequisites.html
统一整理了符号约定(B/T/S/V/d_model/H/H_kv/D/N/M
等十几个张量符号的语义和 shape),遇到 confusion 再翻,不必先修。

3. 三阶段学习路径(官方建议)
课程体量大,第一次学不要全修。官方建议三遍走:
- 第一遍(主干必修):Ch01-Ch06,搭一个能 forward 的 GPT——必须写代码作业
- 第二遍(让它跑起来):Ch07-Ch08,训练一个小模型并让它生成文本——重点看 loss / optimizer / sampling 的输入输出 shape
- 第三遍(进阶选读):Ch09-Ch10,微调、对齐、推理优化——先建概念地图,再回头补公式
4. 知识地图可视化
每章顶部都有 SVG 知识地图,标出"学这章前需要知道什么 / 这章解决什么 / 学完后接着读什么"。前后章通过张量流强关联,不跳章效果更好。
怎么用
方式一:本地起服务(推荐)
1 | git clone https://github.com/garry-x/llm-course |
然后打开 http://localhost:8080。serve.sh
会自动检测端口占用并询问是否终止占用进程。
方式二:跑作业
1 | pip install -r requirements.txt |
requirements.txt 只有 4 个核心包:
1 | torch>=2.0.0 |
每个作业目录(assignments/chXX_xxx/)包含 4 个文件:
README.md— 任务说明starter.py— 你的代码起点reference_solution.py— 参考实现tests.py— 验证脚本
跑测试统一用仓库根的 run_assignment_tests.py。
适合谁
- 懂 Python + 基础线性代数,想从代码层真正"造一个 LLM"
- 已经会用 transformers / LangChain,但想搞清里面到底怎么算的
- 做训练 / 推理工程,需要把 MLA、MoE、KV Cache、FlashAttention、GRPO 从"听过"变成"能写能调"
- 不适合:只想调 API 调 prompt 的纯应用层;完全没写过 Python 的纯数学背景
总结
这门课的稀缺之处在于"代码深度 + 工程视野"同时拉满。251 个 section + 11 个编程作业 + 9 份附录,每个知识点都回答三件事:数学上解决什么问题、代码上怎么落到 PyTorch 张量、工程上引入了什么 cost/speed/quality 的取舍。
如果你认真想搞懂 LLM 全链路,推荐从 Ch01 BPE 开始,把
assignments/ch01_bpe/starter.py 写完,跑通
tests.py,然后决定要不要继续往下走。
Star / 提 Issue / 提 PR 都在 https://github.com/garry-x/llm-course,作者维护活跃。
本文配图来自课程仓库 README 与各 chapter / docs 页面截图,版权归属课程作者 garry-x。