在每一个现代 LLM 的输出层,每一层 Transformer 的 Attention 机制里,都藏着一个同样的函数——Softmax。它看似简单,却承载着从统计力学到深度学习的百年进化。本文将从历史、数学、工程三个维度,尽可能图表化地解构这个“最熟悉的陌生人”。
一、历史由来:从 Boltzmann 到 Bridle
1.1 统计力学的先声(1868)
Softmax 的数学原型可以追溯到 19 世纪统计力学家 Ludwig Boltzmann 提出的 Boltzmann 分布。在热力学中,一个系统处于某个状态 \(i\) 的概率与能量 \(E_i\) 的负指数成正比:
\[ P(i) \propto e^{-E_i / kT} \]
其中 \(k\) 是 Boltzmann 常数,\(T\) 是温度。这个式子的核心思想是:能量越低的状态越可能被采样,但所有状态都有非零概率。
今天的 Softmax 几乎是它的翻版——把能量换成模型输出的“logits”,把温度换成可调的超参数。
1.2 Logistic 回归与多分类问题(1958)
20 世纪 50 年代,David Cox 提出 Logistic 回归,用 Sigmoid 函数将实数映射到 (0,1) 区间以解决二分类问题:
\[ \sigma(z) = \frac{1}{1 + e^{-z}} \]
当统计学家尝试把这个方法推广到 K 个类别 时,他们发现简单地重复 Sigmoid 会导致概率之和不为 1。需要一种新的函数,能够同时完成:
- 每个输出在 (0,1) 区间
- 所有输出之和为 1
- 保持原始 logits 的相对大小关系
1.3 “Softmax” 的命名(1989)
大多数人认为是 John Bridle 在 1989 年的论文 "Training Stochastic Model Recognition Algorithms as Networks can Lead to Maximum Mutual Information Estimation of Parameters" 中正式引入了“Softmax”这个名字。
但其实早在 1986 年,McCullagh 和 Nelder 的《Generalized Linear Models》就已经使用了类似的多类 Logistic 函数。Bridle 的贡献是把它置于神经网络的语境中,并给出了一个有趣的解释:
Softmax 是 Argmax 的“柔化”版本——它保留了“谁最大谁赢”的精神,但用概率分布取代了硬性的 one-hot 选择。
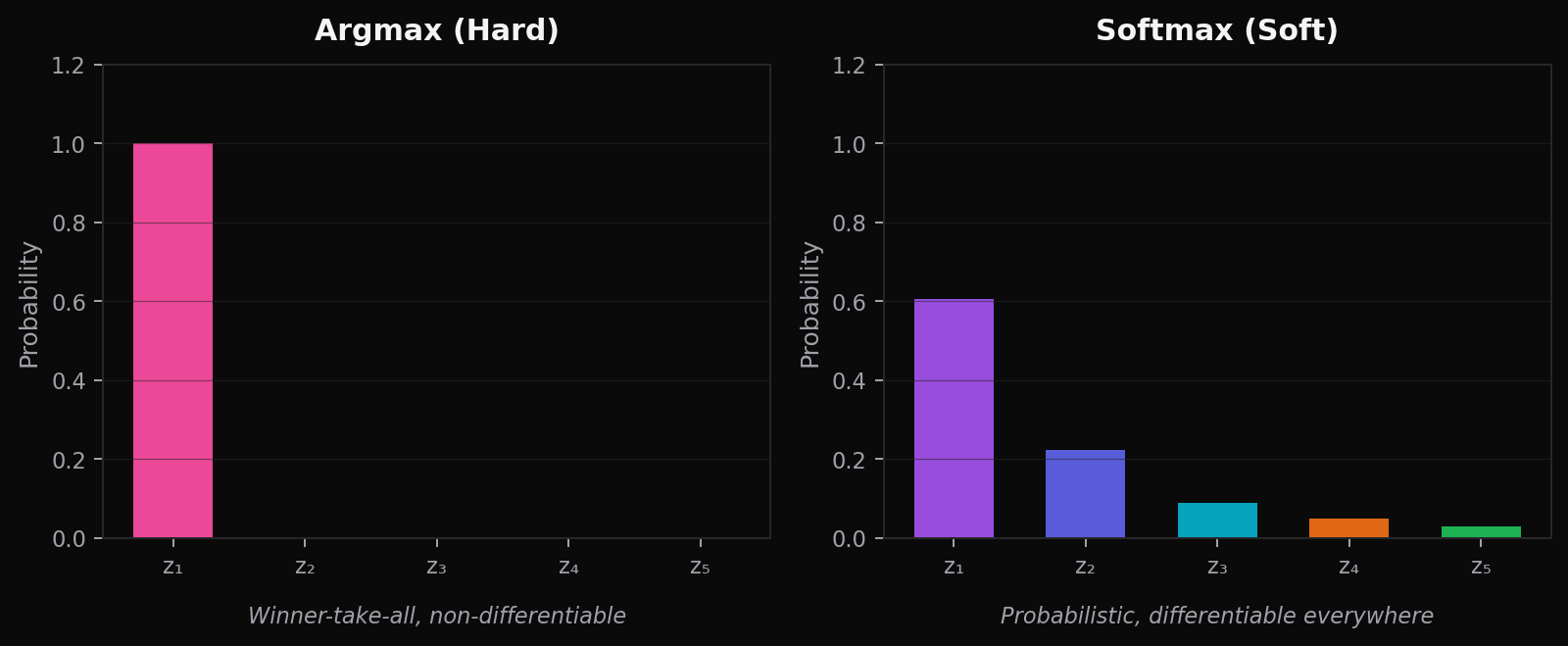
图中左侧的 Argmax 是不可微的“硬决策”,右侧的 Softmax 则是每处可导、每个类别都有非零概率的“软决策”。这个区别直接决定了它能被放进神经网络用梯度下降训练,而 Argmax 不行。
1.4 时间线:从物理学到 GPT-3

从 1868 年的热力学到 2020 年的 GPT-3,Softmax 走过了近 160 年。它之所以能在 2017 年 Transformer 出现后成为核心组件,是因为 Attention 机制需要一个能够渲染“关系强度”的归一化函数,而 Softmax 正好符合这一需求。
二、数学本质:为什么是指数?
2.1 定义与公式
对于一个 \(K\) 维的输入向量 \(\mathbf{z} = [z_1, z_2, \dots, z_K]\),Softmax 定义为:
\[ \mathrm{softmax}(z_i) = \frac{e^{z_i}}{\sum_{j=1}^{K} e^{z_j}} \]
这个公式有三个关键性质:
- 正性:\(\forall i,\; p_i > 0\),每个类别都有非零概率
- 归一性:\(\sum_i p_i = 1\),构成有效的概率分布
- 单调性:如果 \(z_i > z_j\),则 \(p_i > p_j\),保持排序关系
2.2 为什么是\(e^x\)?
这是最常被忽视的问题。为什么不用 \(z_i^2\)、\(|z_i|\)、或其他函数?
原因一:指数函数是唯一能把加法变成乘法的函数
\[ e^{a+b} = e^a \cdot e^b \]
这意味着如果你有两个独立的证据来源都支持类别 \(i\),它们的 logits 可以直接相加,而概率则相乘——这正好符合贝叶斯定理的概率更新规则。
原因二:指数族分布
在概率论中,Softmax 是 多项逻辑斯谯回归(Multinomial Logistic Regression) 的自然选择,因为它是指数族分布(Exponential Family)的典型成员,拥有最大熵的性质。简而言之:在信息最少的前提下,Softmax 是最“不偏不倚”的概率分布。
原因三:对比度敏感
\(e^x\) 是“快速增长”的,这让 Softmax 能放大 logits 之间的差异。如果两个 logits 相差 1,它们的概率比会是 \(e^1 \approx 2.718\);相差 2 则是 \(e^2 \approx 7.39\)。这种对比度的放大效应,让模型能够“自信”地选择最可能的类别,同时又不至于完全放弃其他可能性。
三、LLM 中的两大战场
在大语言模型中,Softmax 主要出现在两个关键位置:输出层的 Token 预测头(LM Head)和每层的 Self-Attention 机制。
3.1 输出层:从 logits 到词表概率
当一个 LLM 生成文本时,最后一层的线性层会输出一个维度为 \(|V|\) 的向量,\(|V|\) 是词表大小(例如 GPT-3 的 50,257)。这些原始值就是 logits。
每一个 logit \(z_t\) 表示“模型认为下一个 token 是 \(t\) 的政击度”。Softmax 把这些原始分数转换为概率分布:
\[ P(t_{next} = w_i \mid t_1, \dots, t_n) = \frac{e^{z_{w_i}}}{\sum_{j=1}^{|V|} e^{z_{w_j}}} \]
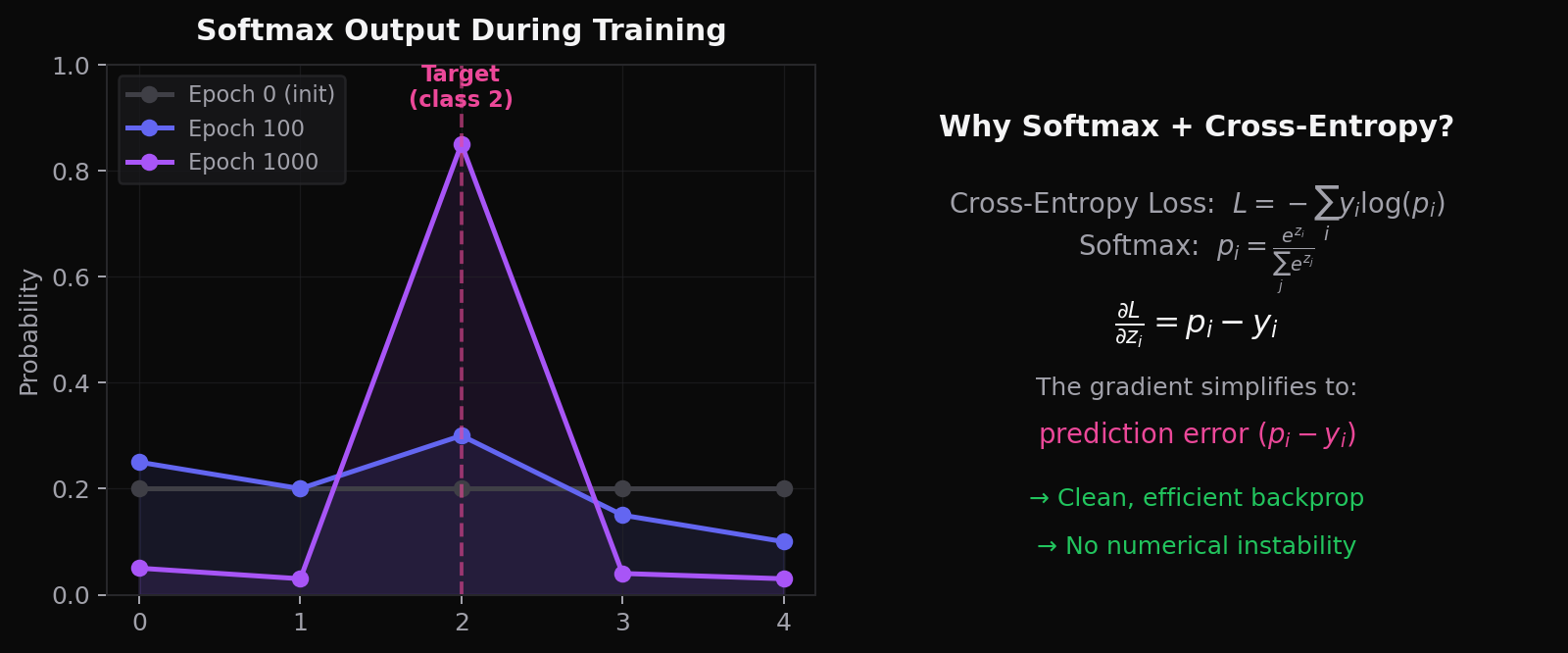
左图展示了训练过程中 Softmax 输出的演化:从初始化的均匀分布,逐渐收敛到目标类别的尖峰。右图则揭示了为什么 Softmax 与 Cross-Entropy 损失函数是“天作之合”——它们的梯度简化后等于 \(p_i - y_i\),即预测误差。这让反向传播极其高效,也是为什么所有主流语言模型都采用这个组合。
3.2 Attention:Softmax 变成了“关系强度”
这是 Softmax 在 LLM 中最具革命性的应用。Transformer 架构中,Softmax 不再只是“输出一个概率分布”,而是被用来将“相似度分数”转换为“加权和为 1 的注意力分布”。
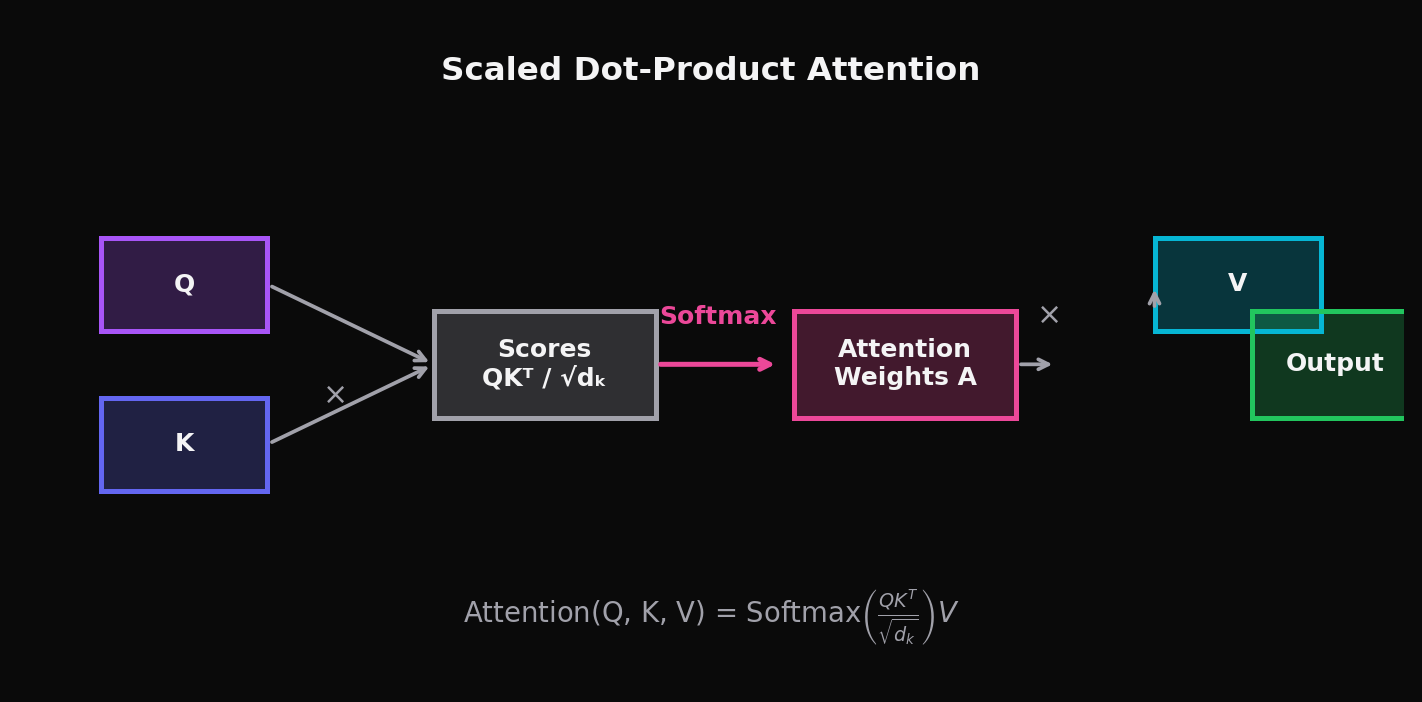
具体流程如下:
- \(Q\) (Query)与 \(K^T\) (Key的转置)相乘,得到原始相关性分数
- 除以 \(\sqrt{d_k}\) 进行 Scale,防止点积数值过大导致 Softmax 极端化
- 通过 Softmax 归一化,得到 Attention 权重
- 权重与 \(V\) (Value)相乘,得到最终输出
这里 Softmax 扮演的角色是关键的:它确保每个 token 在聚合信息时,总是从全局中“注意力”最高的那些位置采样——但不会完全忽视其他位置。
3.3 温度参数:控制“创造力”
在 LLM 的推理阶段,开发者常会用一个叫 Temperature 的超参数来控制输出的“随机性”:
\[ P(i) = \frac{e^{z_i / T}}{\sum_j e^{z_j / T}} \]
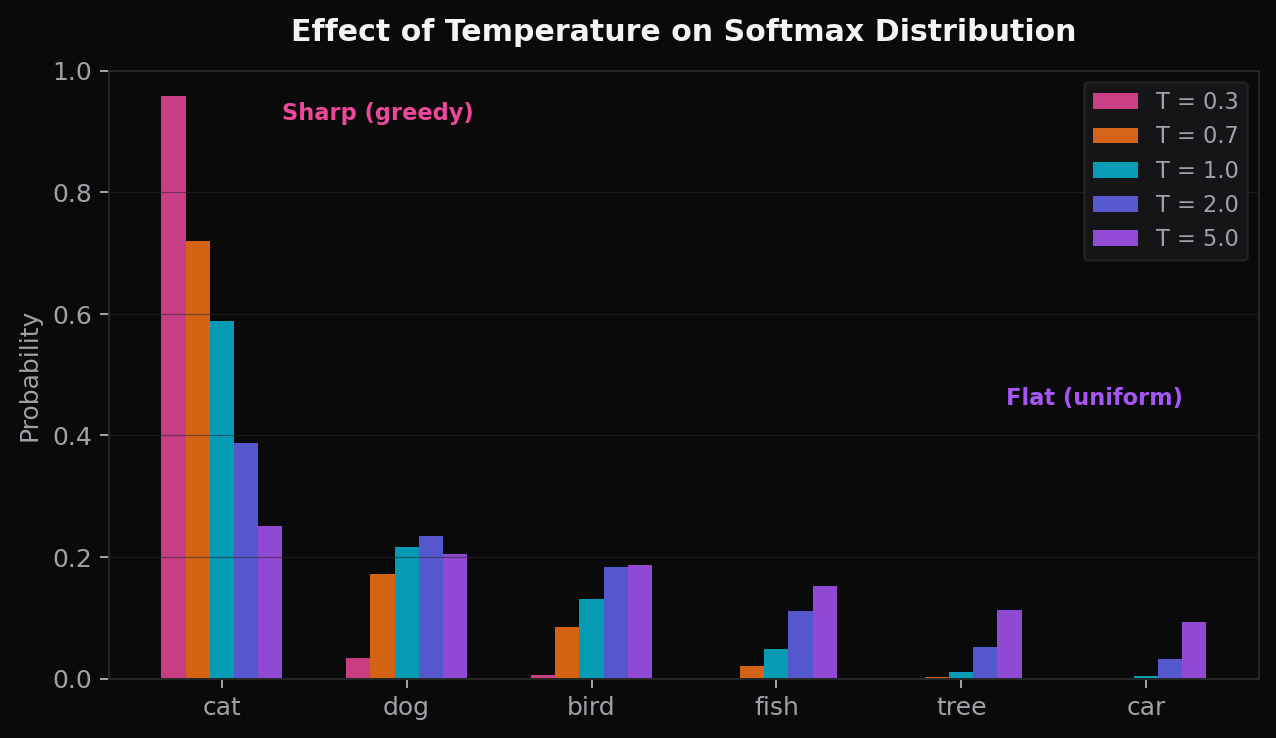
- \(T < 1\)(如 T=0.3):分布变得极端尖锐,几乎等价于 Greedy Decoding。模型变得“自信”、“严肃”,适合任务型场景。
- \(T = 1\)(标准):模型按原始信心度输出。
- \(T > 1\)(如 T=5):分布趋向均匀,模型更愿意尝试低概率的 token,输出更“有创意”。
这个参数的名字也来自统计力学——它就是 Boltzmann 分布里的温度 \(T\)。温度越高,系统越“混乱”,越容易跳出局部最优解。
四、为什么 LLM 选择了 Softmax?
理解了历史和应用,我们来回答最核心的问题:如果从头设计一个 LLM,为什么非得是 Softmax?
4.1 可微分性:端到端训练的前提
这是最直接的原因。神经网络的训练依赖反向传播(Backpropagation),而这需要每个组件都是可微的。Argmax 的导数在绝大多数位置是 0,在切换点不连续——这让梯度流无法传递。
Softmax 则在\(\mathbb{R}^K\) 上每处可导,导数为:
\[ \frac{\partial p_i}{\partial z_j} = p_i (\delta_{ij} - p_j) \]
其中 \(\delta_{ij}\) 是 Kronecker delta。这是一个美丽的结果:Softmax 的 Jacobian 矩阵可以用它自己的输出\(p_i\) 来表达,计算高效。
4.2 与 Cross-Entropy 的天作之合
语言模型通常用 Cross-Entropy Loss 训练:
\[ L = -\sum_i y_i \log(p_i) \]
当 \(p = \mathrm{softmax}(z)\) 时,对 logits \(z_i\) 的梯度简化为:
\[ \frac{\partial L}{\partial z_i} = p_i - y_i \]
这个结果的简洁性是惊人的:
- 数值稳定:没有除法、没有对数的复杂运算
- 直观:梯度就是“预测值减真实标签”
- 高效:计算只需一次前向 + 一次反向,复杂度 \(O(K)\)
如果换成其他归一化函数(如简单的 \(\frac{z_i}{\sum z_j}\)),梯度会变得复杂得多,数值上也不稳定。
4.3 数值稳定性:“减去最大值”的魔法
在实际工程中,LLM 的 logits 经常是非常大的数(比如 100 或
-100)。如果直接计算 \(e^{1000}\),浮点数会直接溢出成
inf。

解决方案是在计算前,先把所有 logits 减去它们的最大值:
\[ \mathrm{softmax}(z_i) = \frac{e^{z_i - \max(\mathbf{z})}}{\sum_j e^{z_j - \max(\mathbf{z})}} \]
这不会改变最终结果,因为分子分母同时除以 \(e^C\) 会相互抵消。但是最大的那一项变成 \(e^0 = 1\),其他项都 \(\leq 1\),完全避免了溢出。这个简单的 trick 是每个深度学习框架必备的优化。
4.4 概率归一化的本质优势
在 Attention 中,Softmax 不仅仅是“把数变正”,它还具备三个与语义高度契合的性质:
- 单调性:较高的相关分数\(\rightarrow\)较高的注意力,符合“更相关就更重要”的直觉
- 差异放大:\(e^x\) 会放大明显的匹配与弱匹配之间的差距,让模型“聚焦”于真正重要的 token
- 总和为 1:让 Attention 输出可以视为对 Value 向量的几何加权平均,维护了表征空间的线性结构
五、局限性与前沿探索
Softmax 并非完美无缺。在超大词表的场景下(如 100K+ tokens),它有一个显著的缺陷:
5.1 长尾问题
Softmax 的指数特性会导致概率分布极度不均匀。在一个\(|V| = 50{,}257\)的词表中,绝大多数的\(p_i\) 会接近于零,只有前几百个 token 的概率显著非零。这导致:
- 训练时,流量和梯度集中在头部几个 token,尾部难以学习
- 采样时,低频词几乎从未被选中,模型的“词汇量”被过度压缩
5.2 替代方案
研究界已经提出了几种替代品:
| 方法 | 核心思想 | 优势 | 局限 |
|---|---|---|---|
| Sparsemax | 将概率分布映射到简单形,允许\(p_i = 0\) | 真正稀疏,解释性强 | 不可微分点处更多 |
| Spherical Softmax | 在球面上归一化,而非简单分布 | 避免极端尖锐 | 计算更复杂 |
| Adaptive Softmax | 根据词频分层,少用\(e^x\) | 大幅加速训练 | 只适用训练阶段 |
| Logit Scaling | 用其他函数替代\(e^x\) | 更灵活 | 理论保证弱 |
然而直到 2026 年,Softmax 仍然是 LLM 的绝对主流。原因很简单:它的组合性质(可微、高效、稳定、与 Cross-Entropy 兼容)在工程实践中的优势太大,覆盖了它的理论缺陷。
六、总结
Softmax 的故事是一个经典的“旧理论遇上新场景”的案例:
- 1868 年,Boltzmann 用它描述分子的热力学行为
- 1989 年,Bridle 用它解决多分类神经网络的训练问题
- 2017 年,Vaswani 等人用它让 Transformer 能够“注意”到语句的关键部分
- 2026 年,每个 GPT、Claude、Llama 的每一次生成,都离不开这个\(\frac{e^{z_i}}{\sum_j e^{z_j}}\)
它之所以能成为 LLM 的基石,不仅仅因为它“能用”,更因为它在数学上满足了一组严格的约束:可微、归一、单调、数值稳定、与最小化目标兼容。当你下次看到 LLM 输出一个句子时,记得想想:这句话里的每一个字,都曾在一个由指数函数決定的概率分布中被“抽取”出来。那个简洁的分数,正是整个现代 NLP 的术语底座。
参考文献
- Bridle, J. S. (1989). "Training Stochastic Model Recognition Algorithms as Networks can Lead to Maximum Mutual Information Estimation of Parameters." NeurIPS.
- Vaswani, A., et al. (2017). "Attention Is All You Need." NeurIPS.
- Martins, A., & Astudillo, R. (2016). "From Softmax to Sparsemax: A Sparse Model of Attention and Multi-Label Classification." ICML.
- Grave, É., et al. (2017). "Efficient Softmax Approximation for GPUs." ICML.
- McCullagh, P., & Nelder, J. A. (1989). Generalized Linear Models. Chapman & Hall.